
캐글(Kaggle)의 여러가지 입문용 데이터 분석 문제 중 가장 대중적인 타이타닉에 대해서 써보고자 한다.
필자는 Machine Learning을 아예 써본 적이 없다.
기회가 되어서 Kaggle이라는 사이트를 알게 되었고 흥미가 생겨서 시도를 해봤고 그 결과에 대한 정리를 하고자 한다.
타이타닉(Titanic) 생존자 예측
Dataset
https://www.kaggle.com/competitions/titanic/data
Titanic - Machine Learning from Disaster | Kaggle
www.kaggle.com
Kaggle 페이지의 Titanic 챌린지에 data부분으로 가면 아래와 같이 3개의 데이터가 존재한다.
이후에 있을 데이터 가공에 필요하기 때문에 작업 경로에 붙여 넣어야 한다.
Pre-Processing
import pandas as pd
train = pd.read_csv('./input/train.csv')
test = pd.read_csv('./input/test.csv')
gender_submission = pd.read_csv('./input/gender_submission.csv')
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
sns.set()
import warnings
warnings.filterwarnings("ignore")
Data Processing
데이터를 가공하기 앞서서 확인해야 할 것이 있다.
- 어떤 type의 데이터를 가지고 있는지
- Column의 값에 Null 데이터가 존재하는지
- 데이터를 Machine Learning에 올렸을 때 직관적으로 판단하기 쉬운지
test.head()데이터 값을 확인해보면 아래와 같은 Column으로 되어 있는 것을 볼 수 있다.

test.info()이번에는 데이터의 type과 Null의 유무에 대해서 확인하겠다.
type이 object인 것들은 숫자로 변형해줘야 하며,
데이터에 null 값이 들어있으면 Machine Learning의 학습에 문제가 생길 수 있기 때문에 표준값으로 치환해야한다.
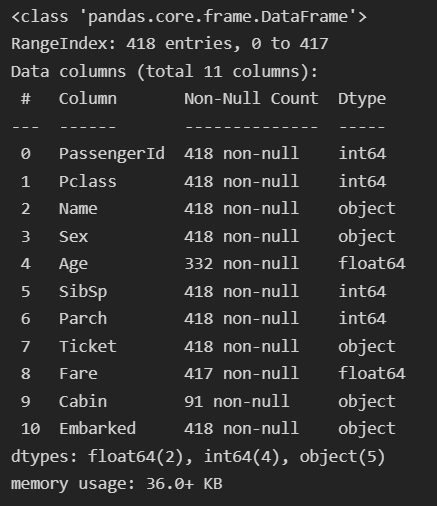
위의 결과는 test를 대상으로 확인했지만 train을 대상으로도 확인하면
Age, Fare, Cabin, Embarked에 null 값이 있는 것을 확인 할 수 있다.
이제부터는 값들에 대해서 가공화를 작업하겠다.
성별(Sex)
test['Sex'].head()성별의 데이터가 어떻게 표현되는지 head()를 통해서 보면
아래와 같이 male 혹은 female로 나타난다.
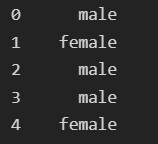
두가지 방법으로 해당 데이터를 숫자로 치환이 가능하다.
첫번째로는 아래와 같이 map함수를 사용해서 직접적으로 데이터에 상응하는 숫자를 부여하는 것이다.
train_test = [train,test]
sex_mapping = {"male":0, "female":1 }
for dataset in train_test_data:
dataset['Sex'] = dataset['Sex'].map(sex_mapping)이보다 간단하게 하는 방법으로는 astype('category').cat.codes를 사용하는 것이다.
numerical 데이터로 변경하고 싶은 categorical(범주형) 컬럼을 정하고 강제 형변환 후
cat.codes를 호출해 숫자형 값으로 리턴한다.
단점으로는 해당 숫자가 어떤 값으로 매핑되어 있는지 확인이 어렵다는 것이다.
train_test = [train,test]
for dataset in train_test:
dataset['Sex'] = dataset['Sex'].astype('category').cat.codes+
해당 feature가 실제로 생존에 영향을 주는지는 위와 같은 단순 데이터로는 판단하기 어려울 수 있다.
그렇기 때문에 여러가지 차트와 그래프의 사용으로 판단을 용이하게 할 수 있다.
여러가지가 존재하지만 여기서는 두가지만 사용하겠다
첫번째로는 Bar chart이다.
def bar_chart(feature):
survived = train[train['Survived']==1][feature].value_counts()
dead = train[train['Survived']==0][feature].value_counts()
df = pd.DataFrame([survived,dead])
df.index = ['Survived','Dead']
df.plot(kind='bar',stacked=True, figsize=(10,5))두번째로는 Graph(?)이다.
# 범위 설정 없으면 전체 범위에 대한 그래프
# 범위 설정 하면 해당 범위에 대한 그래프
def graph_chart(feature,min=0,max=0):
facet = sns.FacetGrid(train, hue="Survived",aspect=4)
facet.map(sns.kdeplot,feature,shade= True)
facet.set(xlim=(0, train[feature].max()))
facet.add_legend()
if min == 0 and max == 0:
plt.show()
else:
plt.xlim(min,max)
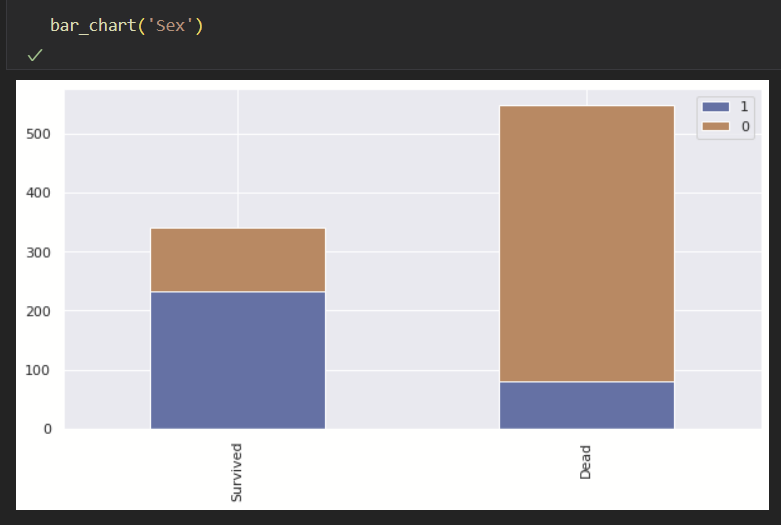
실제 Bar chart로 확인하면 사망자의 비율이 남성이 확실하게 더 높은 것으로 보인다.
해당 feature는 생존자 판단을 위해 중요한 데이터인 것을 알 수 있다.
이름(Name)
test['Name'].value_counts()name 데이터를 확인해보자.
확인하면 아래와 같은 데이터가 나오는데 이를 가공해야 한다.
가공은 미국의 호칭들을 기반으로 진행하였다.
for dataset in train_test:
dataset['Title'] = dataset['Name'].str.extract(' ([A-Za-z]+)\.', expand=False)
title_mapping = {"Mr": 0, "Miss": 1, "Mrs": 2,
"Master": 3, "Dr": 4, "Rev": 4, "Col": 4, "Major": 4, "Mlle": 1,"Countess": 4,
"Ms": 1, "Lady": 4, "Jonkheer": 4, "Don": 4, "Dona" : 4, "Mme": 2,"Capt": 4,"Sir": 4 }
for dataset in train_test:
dataset['Title'] = dataset['Title'].map(title_mapping)map함수를 통하여 진행하였으며 이전과 동일하게 cat.codes를 사용해도 무관하다.
이를 bar chart를 통해서 확인하면 아래와 같다.
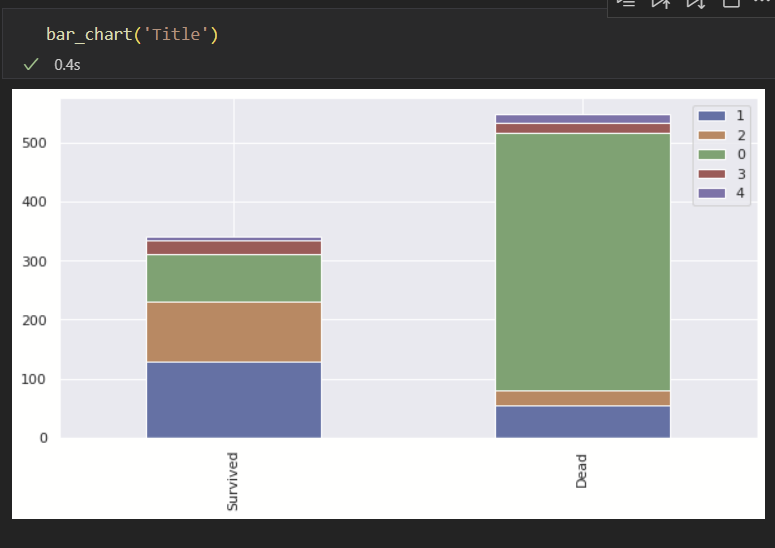
Miss(미혼여성)의 생존률이 가장 높으며 그 다음으로는 Mrs(기혼여성)가 높다.
뿐만 아니라 Master 호칭을 쓰는 경우 생존률이 높은 것을 볼 수 있다.
(※확인해보니 Master는 어린 소년들을 대상으로 사용한다고 함.)
나이(Age)
나이에는 null을 포함하는 데이터가 존재한다.
그렇기 때문에 해당 데이터에 값을 넣어야지 학습에 문제가 생기지 않는다.
하지만 정확한 나이를 알 수 없다.
여러가지 블로그를 참조한 결과 Title로 그룹화한 Age의 중간 값을 넣어준 결과가
가장 높은 예측률을 가져오는 것을 알 수 있었다.
for dataset in train_test:
dataset['Age'].fillna(dataset.groupby('Title')['Age'].transform('median'), inplace=True)위와 같이 진행을 하였고 null값을 확인하면 없는 것을 알 수 있다.
추가로 그래프를 통해서 확인을 해보면 해당 데이터가 실제로 얼마나 중요한지 알 수 있다.
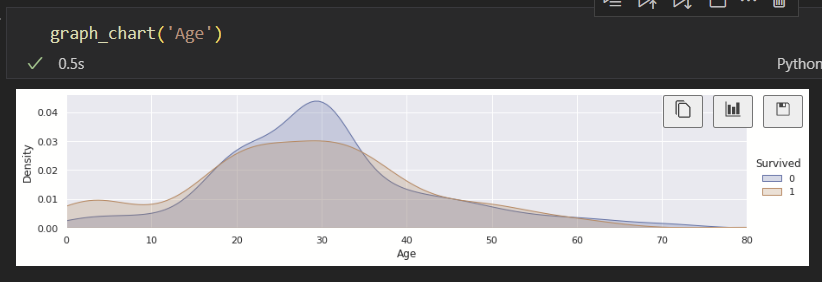
그래프를 보면 나이가 어리거나 많을 수록 생존률이 높은 것을 알 수 있다.
Machine Learning이 학습하기 좋은 데이터이기 때문에 구간화(Binning)작업을 해주겠다.
작업은 10살 단위로 묶어서 구간화를 진행하였다.
for dataset in train_test:
dataset.loc[ dataset['Age'] <= 10, 'Age'] = 0
dataset.loc[(dataset['Age'] > 10) & (dataset['Age'] <= 16), 'Age'] = 1
dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 20), 'Age'] = 2
dataset.loc[(dataset['Age'] > 20) & (dataset['Age'] <= 26), 'Age'] = 3
dataset.loc[(dataset['Age'] > 26) & (dataset['Age'] <= 30), 'Age'] = 4
dataset.loc[(dataset['Age'] > 30) & (dataset['Age'] <= 36), 'Age'] = 5
dataset.loc[(dataset['Age'] > 36) & (dataset['Age'] <= 40), 'Age'] = 6
dataset.loc[(dataset['Age'] > 40) & (dataset['Age'] <= 46), 'Age'] = 7
dataset.loc[(dataset['Age'] > 46) & (dataset['Age'] <= 50), 'Age'] = 8
dataset.loc[(dataset['Age'] > 50) & (dataset['Age'] <= 60), 'Age'] = 9
dataset.loc[ dataset['Age'] > 60, 'Age'] = 10
Pclass
이번에는 티켓의 Class 차이에 따른 생존률이다.
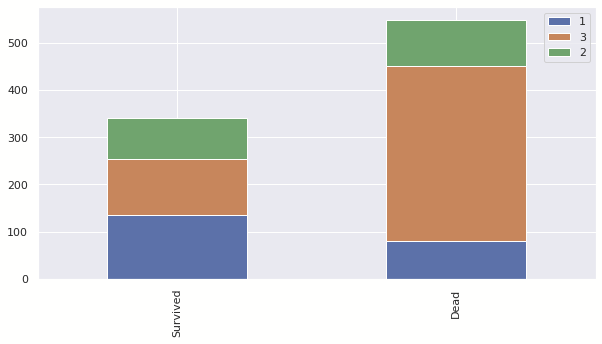
해당 차트를 Class별 티켓의 비율을 고려해서 보면 등급이 높을 수록 생존률이 높은 것을 알 수 있다.
이를 통해서 티켓의 Class가 높을 수록 생존률이 높은 것을 알 수 있다.
선착장(Embarked)
null이 존재하기 때문에 대체값을 넣어야 한다.
이전 Age에서는 Title에 속하는 Age의 중간값을 넣어줬지만 선착장은 숫자로 나오지 않기 때문에
가장 많은 선착장을 기준으로 넣어 주고자 한다.
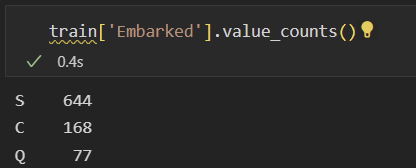
확인하면 S선착장에서 가장 많은 숫자의 승객이 탄 것을 알 수 있다.
그렇기 때문에 빈칸의 Embarked에는 S를 넣어주겠다.
for dataset in train_test:
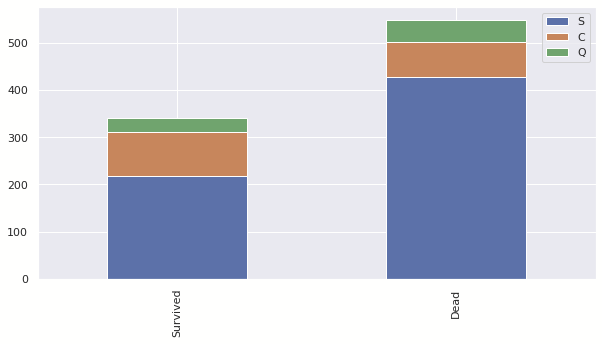
dataset['Embarked'] = dataset['Embarked'].fillna('S')이후 해당 데이터가 실제로 학습에 도움이 되는지 판단 해보자.
아래 차트를 확인하면 C > Q > S 순으로 생존률이 높은 것을 알 수있다.
이로 인해서 해당 데이터는 생존률 판단에 도움이 되는 것으로 판단된다.
이후 가공화 작업을 거쳐준다.
embarked_mapping = {"S":0, "C":1, "Q":2}
for dataset in train_test_data:
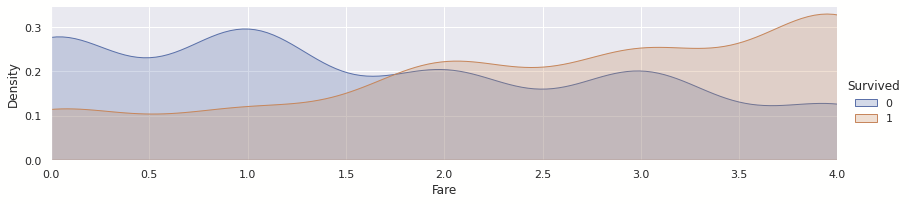
dataset['Embarked'] = dataset['Embarked'].map(embarked_mapping)요금(Fare)
요금도 위와 동일하게 진행된다.
for dataset in train_test:
dataset["Fare"].fillna(dataset.groupby("Pclass")["Fare"].transform("median"), inplace=True)pandas의 qcut을 통하여 5개의 구간으로 분할하였다.
for dataset in train_test:
dataset['Fare'] = pd.qcut(dataset['Fare'], 5)
dataset['Fare'] = dataset['Fare'].astype('category').cat.codes그래프를 보면 확연하게 차이가 나는 것을 알 수 있다.
해당 데이터도 학습을 위한 중요한 데이터인 것을 알 수 있다.
선실 위치(Cabin)
Cabin 데이터를 확인하면 C85, C123... 과 같이 여러가지 값들이 붙는 것을 알 수 있다.
값의 숫자 부분은 사용하지 않을 것이며 알파벳 부분만 사용할 것이다.
이외의 작업은 위와 동일하다.
cabin_mapping = {"A": 0, "B": 0.4, "C": 0.8, "D": 1.2, "E": 1.6, "F": 2, "G": 2.4, "T": 2.8}
for dataset in train_test:
dataset['Cabin'] = dataset['Cabin'].str[:1]
dataset['Cabin'] = dataset['Cabin'].map(cabin_mapping)
dataset["Cabin"] = dataset.groupby("Pclass")["Cabin"].transform("median")
동승한 형제 또는 배우자 수(SibSp),
동승한 부모 또는 자녀 수(Parch)
SibSp와 Parch를 더한 값으로 Family라는 새로운 Column을 만들었다.
추가로 자기 자신인 1도 더해줬다.
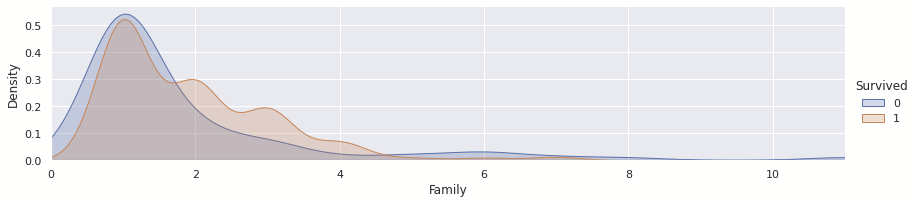
train['Family'] = 1 + train['SibSp'] + train['Parch']
test['Family'] = 1 + test['SibSp'] + test['Parch']보다시피 가족의 수가 많을 수록 생존 확률이 높은 것으로 나타난다.
+Solo
위의 그래프를 보다시피 가족단위로 온 경우에 생존률이 높았다.
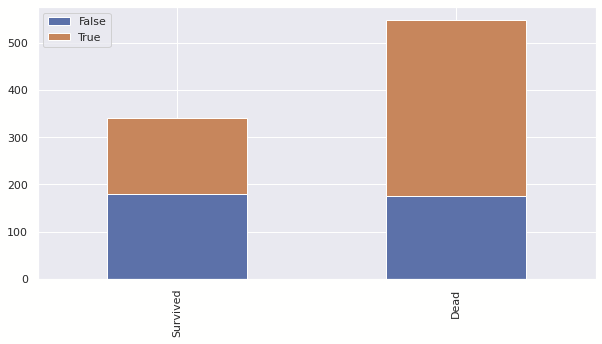
그 결과를 바탕으로 Solo Column을 만들어서 실제로 혼자 탄 경우 생존률이 높은지 확인해봤다.
train['Solo'] = (train['Family'] == 1)
test['Solo'] = (test['Family'] == 1)보다시피 혼자 탑승한 경우에 생존률이 떨어지는 것을 볼 수 있다.
Feature / Label
feature = [
'Pclass',
'SibSp',
'Parch',
'Sex',
'Embarked',
'Family',
'Solo',
'Title',
'Age',
'Cabin',
'Fare',
]
label = [
'Survived',
]
Modeling
해당 부분은 나중에 따로 작성 예정.
+참고 블로그
Kaggle(캐글) 타이타닉 생존자 예측 81% 이상 달성하기
타이타닉 생존자 예측 81% 이상 달성하는 방법에 대하여 알아보겠습니다.
teddylee777.github.io
https://github.com/minsuk-heo/kaggle-titanic/blob/master/titanic-solution.ipynb
GitHub - minsuk-heo/kaggle-titanic: kaggle titanic solution
kaggle titanic solution. Contribute to minsuk-heo/kaggle-titanic development by creating an account on GitHub.
github.com