
728x90
모듈 Import 작업
import pandas as pd
train = pd.read_csv('./input/train.csv')
test = pd.read_csv('./input/test.csv')
sample_submission = pd.read_csv('./input/sample_submission.csv')
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
sns.set()
import warnings
warnings.filterwarnings("ignore")시각화 도구
def bar_chart(feature):
survived = train[train['Transported']==1][feature].value_counts()
dead = train[train['Transported']==0][feature].value_counts()
df = pd.DataFrame([survived,dead])
df.index = ['Transported','Not Transported']
df.plot(kind='bar',stacked=True, figsize=(10,5))# 범위 설정 없으면 전체 범위에 대한 그래프
# 범위 설정 하면 해당 범위에 대한 그래프
def graph_chart(feature,min=0,max=0):
facet = sns.FacetGrid(train, hue="Transported",aspect=4)
facet.map(sns.kdeplot,feature,shade= True)
facet.set(xlim=(0, train[feature].max()))
facet.add_legend()
if min == 0 and max == 0:
plt.show()
else:
plt.xlim(min,max)def scatter(feature):
plt.figure(figsize=(15,7))
sns.scatterplot(data=train,x=train.index,y=feature,hue='Transported',alpha=0.5)Missing Value 처리
train_test = [train, test]
for dataset in train_test:
for cols in dataset.columns:
if((dataset[cols].dtype == 'float64') or (dataset[cols].dtype == 'int64')):
dataset[cols].fillna(dataset[cols].mean(), inplace = True)
else:
dataset[cols].fillna(dataset[cols].mode()[0], inplace = True)train.isnull().sum()
PassengerId 0
HomePlanet 0
CryoSleep 0
Cabin 0
Destination 0
Age 0
VIP 0
RoomService 0
FoodCourt 0
ShoppingMall 0
Spa 0
VRDeck 0
Name 0
Transported 0
dtype: int64
bool값 int로 바꿔주기 나머지 값들은 이후에 작업 진행
for dataset in train_test:
dataset['VIP'] = dataset['VIP'].astype(int)
dataset['CryoSleep'] = dataset['CryoSleep'].astype(int)
서비스에 대해서 하나라도 지불했는지 안했는지 여부 판단
for dataset in train_test:
dataset['cost'] = dataset['RoomService'] + dataset['FoodCourt'] + dataset['ShoppingMall'] + dataset['Spa'] + dataset['VRDeck']for dataset in train_test:
dataset.loc[train['cost'] == 0, 'cost_clean'] = 0
dataset.loc[train['cost'] > 0, 'cost_clean'] = 1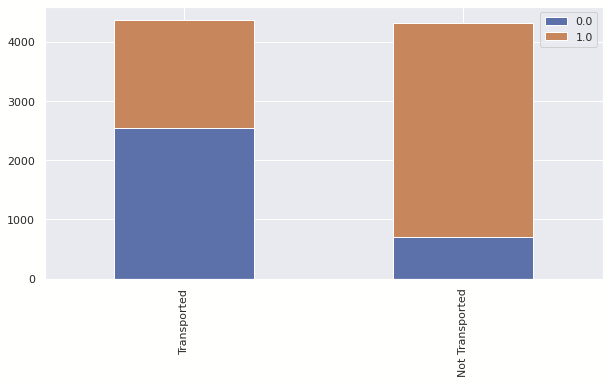
for dataset in train_test:
dataset.loc[ dataset['Age'] <= 10, 'Age_clean'] = 0
dataset.loc[(dataset['Age'] > 10) & (dataset['Age'] <= 16), 'Age_clean'] = 1
dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 20), 'Age_clean'] = 2
dataset.loc[(dataset['Age'] > 20) & (dataset['Age'] <= 26), 'Age_clean'] = 3
dataset.loc[(dataset['Age'] > 26) & (dataset['Age'] <= 30), 'Age_clean'] = 4
dataset.loc[(dataset['Age'] > 30) & (dataset['Age'] <= 36), 'Age_clean'] = 5
dataset.loc[(dataset['Age'] > 36) & (dataset['Age'] <= 40), 'Age_clean'] = 6
dataset.loc[(dataset['Age'] > 40) & (dataset['Age'] <= 46), 'Age_clean'] = 7
dataset.loc[(dataset['Age'] > 46) & (dataset['Age'] <= 50), 'Age_clean'] = 8
dataset.loc[(dataset['Age'] > 50) & (dataset['Age'] <= 60), 'Age_clean'] = 9
dataset.loc[ dataset['Age'] > 60, 'Age_clean'] = 10for dataset in train_test:
dataset['Group'] = dataset['PassengerId'].str[:4]
dataset['ID'] = dataset['PassengerId'].str[-2:]
dataset['Group_Size']=dataset['Group'].map(lambda x: dataset['Group'].value_counts()[x])
dataset.loc[dataset['Group_Size'] == 1, 'Solo'] = 1
dataset.loc[dataset['Group_Size'] != 1, 'Solo'] = 0
dataset['Group'] = dataset['Group'].astype('int')
dataset['ID'] = dataset['ID'].astype('int')HomePlanet_map = {"Earth": 0, "Europa": 1, "Mars": 2}
for dataset in train_test:
dataset['HomePlanet_clean'] = dataset['HomePlanet'].map(HomePlanet_map)Destination_map = {"TRAPPIST-1e": 0, "55 Cancri e": 1, "PSO J318.5-22": 2}
for dataset in train_test:
dataset['Destination_clean'] = dataset['Destination'].map(Destination_map)
for dataset in train_test:
dataset['Cabin_deck'] = dataset['Cabin'].apply(lambda x: x.split('/')[0])
dataset['Cabin_number'] = dataset['Cabin'].apply(lambda x: x.split('/')[1]).astype(int)
dataset['Cabin_side'] = dataset['Cabin'].apply(lambda x: x.split('/')[2])Cabin_deck_map = {"A": 0, "B": 1, "C": 2, "D":3, "E":4, "F":5, "G":6, "T":7}
for dataset in train_test:
dataset['Cabin_deck'] = dataset['Cabin_deck'].map(Cabin_deck_map)Cabin_side_map = {"S": 0, "P": 1}
for dataset in train_test:
dataset['Cabin_side'] = dataset['Cabin_side'].map(Cabin_side_map)for dataset in train_test:
dataset['Cabin_number'] = pd.qcut(dataset['Cabin_number'], 5)
dataset['Cabin_number'] = dataset['Cabin_number'].astype('category').cat.codes
Cabin_deck
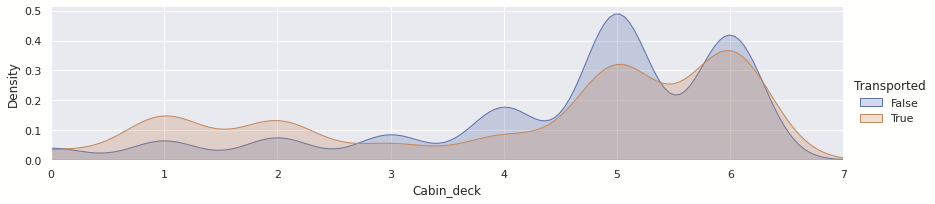
Cabin_side
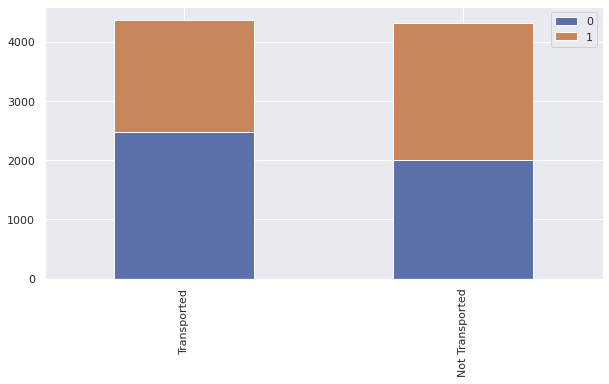
Cabin_number
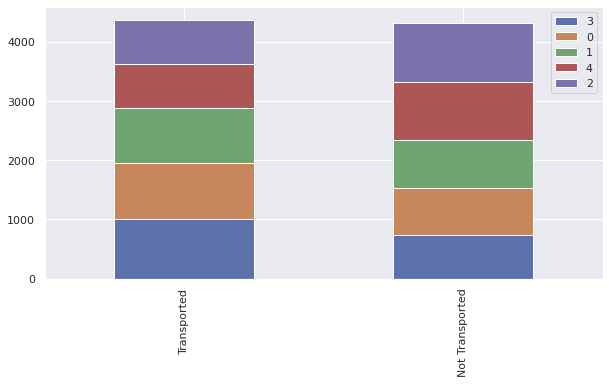
feature = [
'ID',
'CryoSleep',
'Age_clean',
'cost_clean',
'RoomService',
'FoodCourt',
'ShoppingMall',
'Spa',
'VRDeck',
'Group',
'Group_Size',
'Solo',
'HomePlanet_clean',
'Destination_clean',
'Cabin_deck',
'Cabin_number',
'Cabin_side'
]
label = [
'Transported',
]data = train[feature]
target = train[label]from sklearn.model_selection import train_test_split
# Lazypredict Library
import lazypredict
from lazypredict.Supervised import LazyClassifier
#LightGBM library
from lightgbm import LGBMClassifier
# Sklearn Metrics
from sklearn.metrics import classification_report , accuracy_score , confusion_matrix
from IPython.display import clear_outputdef splitted_data(features , label) :
x_train,x_test,y_train,y_test = train_test_split(features, label , test_size = 0.3)
print(f"Shape of x_train : {x_train.shape}")
print(f"Shape of y_train : {y_train.shape}")
print(f"Shape of x_test : {x_test.shape}")
print(f"Shape of y_test: {y_test.shape}")
return x_train,x_test,y_train,y_test
x_train,x_test,y_train,y_test = splitted_data(data , target)
clf = LazyClassifier(verbose=0,
ignore_warnings=True,
custom_metric=None,
predictions=False,
random_state=12,
classifiers='all')
models, predictions = clf.fit(x_train , x_test , y_train , y_test)models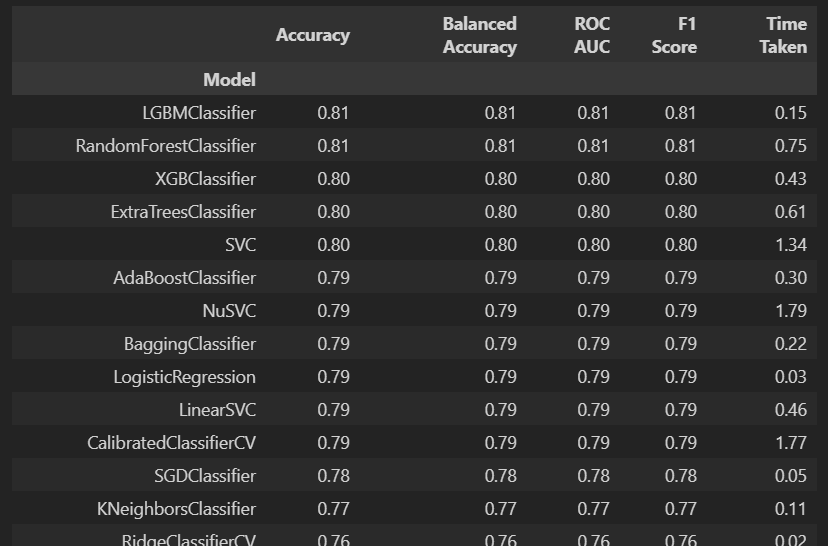
lgbm_classifier = LGBMClassifier(random_state = 42 )
lgbm_classifier.fit(x_train,y_train)y_pred = lgbm_classifier.predict(x_test)
score = accuracy_score(y_test , y_pred)
percentage = score * 100
print(f"Accuracy Score: {percentage:.2f}%")Accuracy Score: 81.21%
xx_test = test[feature]
sample_submission['Transported'] = lgbm_classifier.predict(xx_test)
sample_submission.to_csv('6-submission.csv',index=False)